
This article continues where Docker Swarm Introduction left. I will assume that you have at least a basic knowledge how Swarm in Docker v1.12+ works. If you don’t, please read the previous article first.
The fact that we can deploy any number of services inside a Swarm cluster does not mean that they are accessible to our users. We already saw that the new Swarm networking made it easy for services to communicate with each other.
Let’s explore how we can utilize it to expose them to the public. We’ll try to integrate a proxy with the Swarm network and further explore benefits version v1.12 brought.
A lot changed since I published that article. The Swarm as a standalone container is deprecated in favor of Swarm Mode bundled inside Docker Engine 1.12+. On the other hand, the Docker Flow: Proxy advanced and became more feature rich and advanced. I suggest you check out the project README instead this article.
Before we proceed, we need to setup a cluster we’ll use for the examples.
Environment Setup
The examples that follow assume that you have Docker Machine version v0.8+ that includes Docker Engine v1.12+. The easiest way to get them is through Docker Toolbox.
If you are a Windows user, please run all the examples from Git Bash (installed through Docker Toolbox).
I won’t go into details of the environment setup. It is the same as explained in the Docker Swarm Introduction article. We’ll set up three nodes that will form a Swarm cluster.
docker-machine create -d virtualbox node-1
docker-machine create -d virtualbox node-2
docker-machine create -d virtualbox node-3
eval $(docker-machine env node-1)
docker swarm init \
--advertise-addr $(docker-machine ip node-1) \
--listen-addr $(docker-machine ip node-1):2377
TOKEN=$(docker swarm join-token -q worker)
eval $(docker-machine env node-2)
docker swarm join \
--token $TOKEN \
$(docker-machine ip node-1):2377
eval $(docker-machine env node-3)
docker swarm join \
--token $TOKEN \
$(docker-machine ip node-1):2377
Now that we have the Swarm cluster, we can deploy a service.

Docker Swarm cluster with three nodes
Deploying Services To The Cluster
To experiment the new Docker Swarm networking, we’ll start by creating two networks.
eval $(docker-machine env node-1) docker network create --driver overlay proxy docker network create --driver overlay go-demo
The first one (proxy) will be used for the communication between the proxy and the services that expose public facing APIs. We’ll use the second (go-demo) for all containers that form the go-demo service. It consists of two containers. It uses MongoDB to store data and vfarcic/go-demo as the back-end with an API.
We’ll start with the database. Since it is not public-facing, there is no need to add it to the proxy. Therefore, we’ll attach it only to the go-demo network.
docker service create --name go-demo-db \ --network go-demo \ mongo
With the database up and running, we can deploy the back-end. Since we want our external users to be able to use the API, we should integrate it with the proxy. Therefore, we should attach it to both networks (proxy and go-demo).
docker service create --name go-demo \ -e DB=go-demo-db \ --network go-demo \ --network proxy \ vfarcic/go-demo
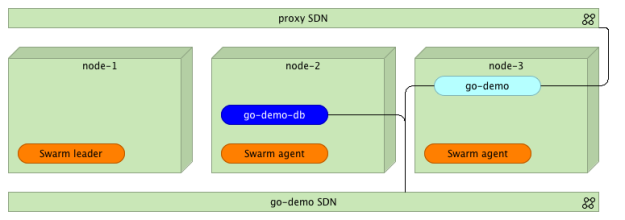
Docker Swarm cluster with three nodes, two networks, and a few containers
Now both containers are running somewhere inside the cluster and are able to communicate with each other through the go-demo network. Let’s bring the proxy into the mix. We’ll use HAProxy. The principles we’ll explore are the same no matter which one will be your choice.
Please note that we did not specify ports. That means the neither containers are accessible from outside the go-demo network.
Setting Up a Proxy Service
We can implement the proxy in a couple of ways. One would be to create a new image based on HAProxy and include configuration files inside it. That approach would be a good one if the number of different services is relatively static. Otherwise, we’d need to create a new image with a new configuration every time there is a new service (not a new release).
The second approach would be to expose a volume. That way, when needed, we could modify the configuration file instead building a whole new image. However, that has downsides as well. When deploying to a cluster, we should avoid using volumes whenever that’s not necessary. As you’ll see soon, a proxy is one of those that do not require a volume. As a side note, --volume has been replaced with the docker service argument --mount.
The third option is to use one of the proxies designed to work with Docker Swarm. In this case, we’ll use vfarcic/docker-flow-proxy container, created from the Docker Flow: Proxy project. It is based on HAProxy with additional features that allow us to reconfigure it by sending HTTP requests.
Let’s give it a spin.
docker service create --name proxy \
-p 80:80 \
-p 443:443 \
-p 8080:8080 \
--network proxy \
-e MODE=swarm \
vfarcic/docker-flow-proxy
We opened ports 80 and 443 that will serve Internet traffic (HTTP and HTTPS). The third port is 8080. We’ll use it to send configuration requests to the proxy. Further on, we specified that it should belong to the proxy network. That way, since go-demo is also attached to the same network, the proxy can access it through the SDN.
Through the proxy we just run we can observe one of the cool features of the network routing mesh. It does not matter on which server the proxy is running. We can send a request to any of the nodes and Docker network will make sure that it is redirected to one of the proxies.
The last argument is the environment variable MODE that tells the proxy that containers will be deployed to a Swarm cluster. Please consult the project README for other combinations.

Docker Swarm cluster with the proxy service
Please note that the proxy, even though it is running inside one of the nodes, is placed outside to illustrate logical separation better.
Before we proceed, let’s confirm that the proxy is running.
docker service ps proxy
We can proceed if the Last state is Running. Otherwise, please wait until the service is up and running.
Now that the proxy is deployed, we should let it know about the existence of the go-demo service.
curl "$(docker-machine ip node-1):8080/v1/docker-flow-proxy/reconfigure?serviceName=go-demo&servicePath=/demo&port=8080"
The request was sent to reconfigure the proxy specifying the service name (go-demo), URL path of the API (/demo), and the internal port of the service (8080). From now on, all the requests to the proxy with the path that starts with /demo will be redirected to the go-demo service.
We can test that the proxy indeed works as expected by sending an HTTP request.
curl -i $(docker-machine ip node-1)/demo/hello
The output of the curl command is as follows.
HTTP/1.1 200 OK Date: Mon, 18 Jul 2016 23:11:31 GMT Content-Length: 14 Content-Type: text/plain; charset=utf-8 hello, world!
The proxy works! It responded with the HTTP status 200 and returned the API response hello, world!.
Please note that it does not matter to which node we send the request. Since Docker networking (routing mesh) takes care of load balancing, we can hit any of the servers. As an example, let’s send the same request but, this time, to the node-3.
curl -i $(docker-machine ip node-3)/demo/hello
The result is still the same.
Let’s explore the configuration generated by the proxy.
Proxy Configuration
If you choose to roll-up your own proxy solution, it might be useful to understand how to configure the proxy and leverage new Docker networking features.
Let’s start by examining the configuration Docker Flow: Proxy created for us. We can do that by entering the running container to take a sneak peek at the /cfg/haproxy.cfg file. The problem is that finding a container run by Docker Swarm is a bit tricky. For example, if we deployed it with Docker Compose, the container name would be predictable. It would use __ format. The docker service command runs containers with hashed names. The docker-flow-proxy created on my laptop has the name proxy.1.e07jvhdb9e6s76mr9ol41u4sn. Therefore, to get inside a running container deployed with Docker Swarm, we need to use a filter with, for example, image name.
First, we need to find out on which node the proxy is running.
docker service ps proxy
Please note the value of the node column and make sure that it is used in the command that follows.
docker-machine ssh node-1 # Change node-1 with the node value previously obtained
The command that will output configuration of the proxy is as follows.
docker exec -it \
$(docker ps -q --filter "ancestor=vfarcic/docker-flow-proxy") \
cat /cfg/haproxy.cfg
exit
The important part of the configuration is as follows.
frontend services
bind *:80
bind *:443
option http-server-close
acl url_go-demo path_beg /demo
use_backend go-demo-be if url_go-demo
backend go-demo-be
server go-demo go-demo:8080
The first part (frontend) should be familiar to those who used HAProxy. It accepts requests on ports 80 (HTTP) and 443 (HTTPS). If the path starts with /demo, it will be redirected to the backend go-demo-be. Inside it, requests are sent to the address go-demo on the port 8080. The address is the same as the name of the service we deployed. Since go-demo belongs to the same network as the proxy, Docker will make sure that the request is redirected to the destination container. Neat, isn’t it? There is no need, anymore, to specify IPs and external ports.
The next question is how to do load balancing. How should we specify that the proxy should, for example, perform round-robin across all instances?
Load Balancing
Before we start load balancing explanation, let’s create a few more instances of the go-demo service.
eval $(docker-machine env node-1) docker service scale go-demo=5
Within a few moments, five instances of the go-demo service will be running.

Docker Swarm cluster with go-demo service scaled and the proxy instance
What should we do to make the proxy balance requests across all instances? The answer is nothing. No action is necessary on our part.
Normally, if we wouldn’t leverage Docker Swarm features, we would have something similar to the following configuration mock-up.
backend go-demo-be
server instance_1 <INSTANCE_1_IP>:<INSTANCE_1_PORT>
server instance_2 <INSTANCE_2_IP>:<INSTANCE_2_PORT>
server instance_3 <INSTANCE_3_IP>:<INSTANCE_3_PORT>
server instance_4 <INSTANCE_4_IP>:<INSTANCE_4_PORT>
server instance_5 <INSTANCE_5_IP>:<INSTANCE_5_PORT>
However, with the new Docker networking inside a Swarm cluster, that is not necessary. It only introduces complications that require us to monitor instances and update the proxy every time a new replica is added or removed.
Docker will do load balancing for us. To be more precise, when the proxy redirects a request to go-demo, it is sent to Docker networking which, in turn, performs load balancing across all replicas (instances) of the service. The implication of this approach is that proxy is in charge of redirection from port 80 (or 443) to the correct service inside the network, and Docker does the rest.
Feel free to make requests to the service and inspect logs of one of the replicas. You’ll see that, approximately, one fifth of the requests is sent to it.
Final Words
Docker networking introduced with the new Swarm included in Docker 1.12+ opens a door for quite a few new opportunities. Internal communication between containers and load balancing are only a few. Configuring public facing proxies became easier than ever. We have to make sure that all services that expose a public facing API are plugged into the same network as the proxy. From there on, all we have to do is configure it to redirect all requests to the name of the destination service. That will result in requests traveling from the proxy to Docker network which, in turn, will perform load balancing across all instances.
The question that might arise is whether this approach is efficient. After all, we introduced a new layer. While in the past we’d have only a proxy and a service, now we have Docker networking with a load balancer in between. The answer is that overhead of such an approach is minimal. Docker uses Linux IPVS for load balancing. It’s been in the Linux kernel for more than fifteen years and proved to be one of the most efficient ways to load balance requests. Actually, it is much faster than nginx or HAProxy.
The next question is whether we need a proxy. We do. IPVS used by Docker will not do much more than load balancing. We still need a proxy that will accept requests on ports 80 and 443 and, depending on their paths, redirect them to one service or another. On top of that, we might use it to perform other tasks like SSL handshake, authentication, and so on.
What are the downsides? The first one that comes to my mind are sticky sessions. If you expect the same user to send requests to the same instance, this approach will not work. A separate question is whether we should implement sticky sessions inside our services or as a separate entity. I’ll leave that discussion for one of the next articles. Just keep in mind that sticky sessions will not work with this type of load balancing.
How about advantages? You already saw that simplicity is one of them. There’s no need to reconfigure your proxy every time a new replica is deployed. As a result, the whole process is greatly simplified. Since we don’t need the list of all IPs and ports of all instances, there is no need for tools like Registrator and Consul Template. In the past, one of the possible solutions was to use Registrator to monitor Docker events and store IPs and ports in a key-value store (e.g. Consul). Once information is stored, we would use Consul Template to recreate proxy configuration. There we many projects that simplified the process (one of them being the old version of the Docker Flow: Proxy). However, with Docker Swarm and networking, the process just got simpler.
To Docker Flow: Proxy Or Not To Docker Flow: Proxy
I showed you how to configure HAProxy using Docker Flow: Proxy project. It contains HAProxy with an additional API that allows it to reconfigure the proxy with a simple HTTP request. It removes the need for manual configuration or templates.
On the other hand, rolling up your own solution became easier than ever. With the few pointers from this article, you should have no problem creating nginx or HAProxy configuration yourself.
My suggestion is to give Docker Flow: Proxy a try before you make a decision. In either case, new Docker Swarm networking features are impressive and provide building blocks for more to come.
What Now?
That concludes the exploration of some of the new Swarm and networking features we got with Docker v1.12. In particular, we explored those related to public facing proxies.
Is this everything there is to know to run a Swarm cluster successfully? Not even close! What we explored by now (in this and the previous article) is only the beginning. There are quite a few questions waiting to be answered. What happened to Docker Compose? How do we deploy new releases without downtime? Are there any additional tools we should use?
I’ll try to give answers to those and quite a few other questions in future articles. The next one is dedicated to Distributed Application Bundles.
Don’t forget to destroy the machines we created.
docker-machine rm -f node-1 node-2 node-3
The DevOps 2.1 Toolkit: Docker Swarm
 If you liked this article, you might be interested in The DevOps 2.1 Toolkit: Docker Swarm book. Unlike the previous title in the series (The DevOps 2.0 Toolkit: Automating the Continuous Deployment Pipeline with Containerized Microservices) that provided a general overlook of some of the latest DevOps practices and tools, this book is dedicated entirely to Docker Swarm and the processes and tools we might need to build, test, deploy, and monitor services running inside a cluster.
If you liked this article, you might be interested in The DevOps 2.1 Toolkit: Docker Swarm book. Unlike the previous title in the series (The DevOps 2.0 Toolkit: Automating the Continuous Deployment Pipeline with Containerized Microservices) that provided a general overlook of some of the latest DevOps practices and tools, this book is dedicated entirely to Docker Swarm and the processes and tools we might need to build, test, deploy, and monitor services running inside a cluster.
You can get a copy from Amazon.com (and the other worldwide sites) or LeanPub. It is also available as The DevOps Toolkit Series bundle.
Give the book a try and let me know what you think.

Thanks!
Good post! Thanks for sharing. Looking forward to the next one about DABs…
What about external DNS? Clients will want a single, pretty name to connect to. I could put all my docker nodes in the DNS record, but that’s not resilient to a node failure or outage.
I have the same problem. For now I use keepalived outside the docker swarm, configured to point to 3 nodes of my swarm. The virtual ip address is the one registered in the DNS. If anyone has a better solution, I’d be glad to hear about it.
Please see the answer I gave to Kevin’s question.
Sorry for not replying earlier. To much work to do…
There is no need to put all Docker nodes in the DNS record. It’s enough to put one (a few in case one of the nodes fails). The flow is following:
I think this deserves an article. I’ll write one soon. In the meantime, please let me know if this answers your question. Feel free to contact me on Skype or HangOuts if you’d like chat about it. My info is in the “About” section.
I just finished the first draft of the article that explains better how the proxy works. You can find it in the https://github.com/vfarcic/docker-flow-proxy/blob/master/articles/swarm-mode.md (sections “Scaling the Proxy” and “The Flow Explained”. Can you please let me know if answers your questions.
Pingback: "Use your feelings, Obi-Wan, and find Links you will." – Yoda - Magnus Udbjørg
Great post. Have your looked into blue-green deployments with docker-flow-proxy and Docker Swarm mode?
I’ll start working on blue-green deployments soon. In the meantime, the new Swarm allows you to do rolling upgrades.
Pingback: Container雙周報第15期:Mesosphere執行長:歡迎來到容器2.0時代 - 唯軒科技
Why do you choose to use Proxy external to Docker Swarm? Would it be simpler to use buildt-in LB in this case?
Hi,
Great article but i have the same question here : why not just deploy HAProxy on multiple nodes and do a rolling update of the config? In blue-green approach, un-updated proxy instances will direct requests to the previous version while we update until all instances are reconfigured for the new version. Is there something i’m missing here?
You can, indeed, use that approach. Every time a new service (NOT a new release) is deployed, you can do a rolling update of a proxy. That update would contain new configuration. Another option would be to expose config on the host, make sure it is mounted on all nodes, update config, and send a signal to the proxy to reconfigure itself.
I think it is much easier to send an HTTP request then doing the other two options. Anyways, the end result is, more or less, the same.
Pingback: Docker Online Meetup # 41: Docker Captains Share their Tips and Tricks for Built In Docker Orchestration | Docker Blog
Pingback: Docker Online Meetup # 41: Docker Captains Share their Tips and Tricks for Built In Docker Orchestration | DevOps Home
Please correct me if I’m wrong. I could not finish the practice of setting proxy and finally I found that I should add expose port for go-demo as below. Should I add that or what I miss in the instruction?
docker service create –name go-demo \
-e DB=go-demo-db \
-p 8080 \
–network go-demo \
–network proxy \
vfarcic/go-demo
Great post ! Thank you !
One problem I’m facing with this is how to load balance a distribuable java web app in a tomcat cluster. Outside docker, I do this by configuring haproxy more or less like described here http://www.tokiwinter.com/highly-available-load-balancing-of-apache-tomcat-using-haproxy-stunnel-and-keepalived/.
How would I be able to configure sticky sessions using docker-flow-proxy ?
This type of proxy logic would not work with sticky sessions. The proxy assumes that services are stateless. In general, with Docker we should try to avoid having state baked into services. If you need a session, I’d suggest you store it in something like Redis and, probably, pass some ID with each request.
I’ll look into that solution. Thank you !
Excelent post. As I was using a solution based on consul, consul template and registrator, this feels much simpler, with fewer moving parts on the developer side. The only thing I miss is registrator made the step of registering the service in haproxy innecessary.
Thank you very much
You’re welcome. Please let me know if there is a feature you’re missing or you find a bug.
Thanks for sharing that great guide to setup an automated proxy in front of your docker swarm environment.
You’re very welcome. I hope you found it useful.
Please note that the Docker Flow: Proxy changed a lot since this article was written. I suggest you check the project README (https://github.com/vfarcic/docker-flow-proxy), especially the part that explains a way to set up everything in a fully automated way (https://github.com/vfarcic/docker-flow-proxy/blob/master/articles/swarm-mode-listener.md).
Nice document, providing high-level insight / latest feature on Swarm clustering.
Hi,
Thanks for sharing and I’m enjoying your book too.
I’m still new to the world of docker so forgive me if my question has already been asked and answered, have you got guide showing similar deployment with multiple different services like (go-demo1, go-demo2 etc ) running in the same swarm cluster?
I haven’t done go-demo1 and go-demo2. If you create the go-demo service with its dependencies (go-demo-db), you should have no problem repeating the same with other services.
That being said, I think you’re right. I can add more services to the book. However, in that case, it would be better to add something completely unrelated (not another go-demo). Do you have a suggestion? Can you send me a stack you’d like me to add?
in the case of a second app deployment like go-demo2, is it mandatory to always use the same network as the go-demo1 and proxy (proxy-SDN in your example)?
For segregation and security purpose, could we imagine to create a new network for the go-demo2 and then update the proxy to belong to this new network ? With such setup go-demo1 can’t talk to go-demo2.
Tks
It is not mandatory to use the same network. You can create as many networks as it makes sense for your use case. The only important thing is that services that need to communicate with each others need to be in the same network (no matter which network that is).
In my case, I tend to create a network for each service bundle (e.g. backend + DB) and attach those that should communicate with the proxy to the proxy network as well. So, if there are four services that form two bundles, it would be something like:
service-1-1 and service-2-2 belong to the network network-1 because they need to speak with each other.
service-2-1 and service-2-2 belong to the network network-2 because they need to speak with each other.
service-1-1, service-2-1, and service-proxy belong to the network proxy because they expose a public API that should be available through the proxy.
That was just an example. The point is to enable communication by attaching services to the same network and organize those networks in any way it makes sense for your use-case.
based on your example, if a create a new service 3 and a network-3 attached to that service 3 , but this service must be accessible by the proxy , so it means you have to attach this new network-3 to the proxy service (already created and attached to the network proxy).
I’m using docker 1.12.3 and I didn’t find a command to update the service like :
service update –attach-network network-3 proxy
Or it’s not possible and I have to create a new proxy-3 service attached to the network-3?
Version 1.12.1 had the option to add a network to a running service through “docker update”. However, it did not work so they removed that option. That means that you cannot attach a network to a running service leaving you with two options.
1) Remove a service (e.g. proxy) and create it again with the new network. This is a bad idea since that would make the service unavailable starting from the removal and until it is created again.
2) Create service-3 with both network-3 and proxy networks (or whatever is the name of the network proxy is already attached to).
Indeed option 1) with the recreation of the proxy service with the new network is a bad idea but will assure the segregation between the services (From a container of a service, I can’t curl another service)
For option 2), I’m not sure it assures a segregation between the different services, because they will share all the same network : proxy in that example. I tested this setup and my service-3 can curl other services. Or perhaps I have to define my own IP Adresses…
Now I understand your use case. Can you let me know why you want such a setup? Are you planning to put authentication or some other restriction to the proxy?
Hi Viktor,
Wow, thanks for getting back so quickly. what I meant by go-demo1 and go-demo2 was just an example of running multiple web applications in a cluster of 3 managers and 4 worker nodes using AWS instances.
Basically I am trying to have all infrastructure applications and in-house web tools on the same swarm cluster with same root domain name (*.exmaple.tech) and with docker-flow-proxy as a reverse proxy to route traffic to their subdomains. (jenkins.exmaple.tech, kibana.example.tech, graphitte.example.tech consul.example.tech etc).
That should be very easy to accomplish. You need the “serviceDomain” parameter. You can create your service with “–label com.df.serviceDomain=kibana.example.tech” and swarm-listener will reconfigure the proxy.
Pingback: Networking in Docker Swarm, and why we need a proxy * Security Howto
Hi Viktor,
Please can you help tell me where am going wrong, trying to deploy jenkins inside a swarm cluster but not able to access via url only through the host IP not sure but it looks like am missing some environment variables or lable flags.
docker service create –name jenkins01 -p 8082:8080 -p 50000:50000 -e JENKINS_OPTS=”–prefix=/jenkins” –mount “type=bind,source=/home/username/docker/jenkins/,target=/var/jenkins_home” –constraint ‘node.id == 96i4m5zplyehsa3zzfitxxxxx’ -l com.df.port=8082 -l com.df.serviceDomain=jenkins.test.example.local –network proxy –network jenkins –reserve-memory 300m jenkins:2.7.4-alpine
The swarm-listener only monitors the services with the label “com.df.notify”. Can you add “-l com.df.notify=true” and let me know whether it worked?
If it doesn’t work with the notify label, please ping me on Skype or HangOuts and we’ll take a look at it together. You can find my info in the About section.
Thanks Viktor, the label flag did the job but I have another issue, I can’t seem to access Jenkins UI without adding port number to the url. how would I get to flow-proxy route custom URL like “jenkins.test.example.local” using port 80 rather than “jenkins.test.example.local:8082/jenkins”?
here is the new service command after adding “-l com.df.notify=true”
docker service create –name jenkins01 \
-p 8082:8080 -p 50000:50000 \
-e JENKINS_OPTS=”–prefix=/jenkins” \
-e JAVA_OPTS=-Dhudson.footerURL=http://jenkins.test.example.local \
–mount “type=volume,source=jenkins_vol02,target=/var/jenkins_home,volume-driver=rexray” \
-l com.df.port=8082 \
-l com.df.serviceDomain=jenkins.test.example.local \
-l com.df.notify=true \
-l com.df.servicePath=/var/jenkins_home \
–network proxy –network web-test –reserve-memory 300m jenkins:2.7.4-alpine
Thanks
The command you run contains environment variable JENKINS_OPTS that specified /jenkins as prefix. If the command stays as it is, you should be able to access Jenkins through jenkins.test.example.local/jenkins (without the port). If that works, all you’d have to do is remove JENKINS_OPTS and Jenkins should be accessible through jenkins.test.example.local.
Can you please try it out and let me know if it worked?
Thanks a lot it now works as expected and here is the command I used:
docker service create –name jenkins \
-p 8082:8080 -p 50000:50000 \
-e JAVA_OPTS=-Dhudson.footerURL=http://jenkins.test.example.local \
–mount “type=volume,source=jenkins_vol01,target=/var/jenkins_home” \
-l com.df.port=8082 -l com.df.port=8080 \
-l com.df.serviceDomain=jenkins.test.example.local \
-l com.df.notify=true -l com.df.servicePath=/ \
–network proxy –network web-test –reserve-memory 300m \
jenkins:2.7.4-alpine
The noticeable change I made which got it working for me was changing the servicePath label from “-l com.df.servicePath=/var/jenkins_home” back to “-l com.df.notify=true -l com.df.servicePath=/” .
I’m now trying to create some jenkins agents on the same cluster where the master is running on but having difficulties getting the service to stay up. Here is the command am running
docker service create –name jenkins-agent \
-e COMMAND_OPTIONS=”-master http://jenkins.test.example.local -username $USER -password $PASSWORD -labels ‘docker’ -executor 5″ \
–mode global \
–mount “type=bind,source=/var/run/docker.sock,target=/var/run/docker.sock” \
–mount “type=volume,source=workspace_vol01,target=/workspace,volume-driver=rexray” \
vfarcic/jenkins-swarm-agent
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
1zsicqqyfn3m8r8mbhkuj3 jenkins-agent.1 vfarcic/jenkins-swarm-agent ip-10-210-1-*** Ready Preparing less than a second ago
2mb7o06hs5dz5o750e3y9s _ jenkins-agent.1 vfarcic/jenkins-swarm-agent ip-10-210-1-*** Shutdown Failed 1 seconds ago “task: non-zero exit (255)”
9e4dtjz86prc4bimajg72n _ jenkins-agent.1 vfarcic/jenkins-swarm-agent ip-10-210-1-*** Shutdown Failed 7 seconds ago “task: non-zero exit (255)”
14cm0ttghxil3gqmfkkvas _ jenkins-agent.1 vfarcic/jenkins-swarm-agent ip-10-210-1-*** Shutdown Failed 12 seconds ago “task: non-zero exit (255)”
4sard7t4lzz5rqrqm5xrj _ jenkins-agent.1 vfarcic/jenkins-swarm-agent ip-10-210-1-*** Shutdown Failed 18 seconds ago “task: non-zero exit (255)”
Also using the Rex-Ray driver plugin for persistent storage “ebs volume”
The servicePath label has to match the root URL path of a service. In your case, this is “/”. Please note that such a path will prevent you from forwarding other services through the proxy since “/” matches any path. The solution would be either to add a domain (e.g. jenkins.acme.com) or use a more concrete path differentiator (e.g. /jenkins).
My best guess for the jenkins-agent error is that is cannot find the master running on http://jenkins.test.example.local.
If you want to connect agents with the master running inside the same cluster, the best way is to attach them to the same network. If both the master and the agents belong to the same network, they can reach each other through service name. In that case, the agent’s argument “-master” would be “http://jenkins:8080”.
Feel free to ping me on Skype or HangOuts. If you share your screen, I can guide you through the setup.
Thanks, using the service name works. I was also able to setup a SSL on the proxy with your github article on https://github.com/vfarcic/docker-flow-proxy/blob/master/articles/swarm-mode-listener.md and was very simple as straight forward.
Commands used:
docker service create –name jenkins-agent \
-e COMMAND_OPTIONS=”-master http://jenkins:8080 \
-username $USER -password $PASSWORD \
-labels ‘docker'” \
–network web-test \
–constraint ‘node.id == 5t37n7ibksot0bvcgtowoxxxxxx’ \
–mount “type=bind,source=/var/run/docker.sock,target=/var/run/docker.sock” \
–mount “type=volume,source=workspace_01,target=/workspace,volume-driver=rexray” \
vfarcic/jenkins-swarm-agent
curl -i -XPUT –data-binary @test.example.local.pem “10.212.1.200:8080/v1/docker-flow-proxy/cert?certName=test.example.local.pem&distribute=true”
At the moment am unable to run the Jenkins Agent service in swarm mode=global but seem to work for me with setting ‘–constraint ‘node.id == 5t37n7ibksot0bvcgtowoxxxxxx’ node id of any single manager or worker node in the swarm.
And how do I get Jenkins Agent to connect to master securely using Https instead of HTTP, do I need to expose or publish some ports?
I would recommend against using the “node.id” constraint. That makes your services very fragile and prone to failure. If that node dies, Swarm will not be able to reschedule services to healthy nodes. A better idea is to label your nodes (e.g. production, testing, and so on) and use that to constraint services.
When you communicate through Swarm Overlay network, there is no need to expose any ports. Any service can speak to any other service through any port as long as they belong to the same network.
Thanks, using the service name works. I was also able to setup a SSL on the proxy with your github article on https://github.com/vfarcic/docker-flow-proxy/blob/master/articles/swarm-mode-listener.md and was very simple as straight forward.
Thanks, using the service name works. I was also able to setup a SSL on the proxy with your github article on https://github.com/vfarcic/docker-flow-proxy/blob/master/articles/swarm-mode-listener.md and was very simple as straight forward.
Commands used:
docker service create –name jenkins-agent \
-e COMMAND_OPTIONS=”-master http://jenkins:8080 \
-username $USER -password $PASSWORD \
-labels ‘docker'” \
–network web-test \
–constraint ‘node.id == 5t37n7ibksot0bvcgtowoxxxxxx’ \
–mount “type=bind,source=/var/run/docker.sock,target=/var/run/docker.sock” \
–mount “type=volume,source=workspace_01,target=/workspace,volume-driver=rexray” \
vfarcic/jenkins-swarm-agent
curl -i -XPUT –data-binary @test.example.local.pem “10.212.1.200:8080/v1/docker-flow-proxy/cert?certName=test.example.local.pem&distribute=true”
At the moment am unable to run the Jenkins Agent service in swarm mode=global but seem to work for me with setting ‘–constraint ‘node.id == 5t37n7ibksot0bvcgtowoxxxxxx’ node id of any single manager or worker node in the swarm.
And how do I get Jenkins master to redirect all HTTP traffic to HTTPS and Agent to connect to master securely using HTTPS instead of HTTP, do I need to expose or publish some ports?
docker service create –name jenkins \
-p 8082:8080 -p 50000:50000 \
-e JAVA_OPTS=-Dhudson.footerURL=http://jenkins.test.example.local \
–mount “type=volume,source=jenkins_vol01,target=/var/jenkins_home” \
-l com.df.port=8082 -l com.df.port=8080 \
-l com.df.serviceDomain=jenkins.test.example.local \
-l com.df.notify=true \
-l com.df.servicePath=/ \
–network proxy –network web-test \
–reserve-memory 300m \
jenkins:2.7.4-alpine
Please see the answers from the previous comment.
Additional note is that all communication through Swarm network is secured by default so there’s no real reason to use HTTPS.
Thanks
Excellent article, I tested it but I wanted to scale the proxy for resiliency purpose, in your example it’s only one instance . I used –replicas 4 on 3 nodes , but now I’m forced to execute the commnand
curl “$nodeip$:8080/v1/docker-flow-proxy/reconfigure?serviceName=..” on all the nodes to update the proxy.
Is there a way to update all the proxy config in one call?
Thanks
This article was written when the proxy was in its infancy. It evolved a lot since then.
There is, indeed, the option to scale the proxy and make it auto-configurable. If you are running the cluster in Swarm Mode, please check the https://github.com/vfarcic/docker-flow-proxy/blob/master/articles/swarm-mode-listener.md . The trick is to add “distribute=true” to the reconfigure request or, even better, to use the swarm-listener, and the proxy instance that receives the command to reconfigure will propagate it to all the instances.
Please let me know if you have any trouble with the documentation and I’ll walk you through the process step by step.
Indeed with the trick to add “distribute=true” it works like a charm, thanks!
Hi,
I’m also new to docker in generally, I was looking for but couldn’t find an explanation how to connect service in the swarm with external service concretely database that is not deployed to a container and is running on a separate host. So for example go-demo finding and connecting to external db. Do I need to connect through the proxy service in this case. If this is the case how would that be done with Docker Flow Proxy.
Thanks for the interesting post and the book and Docker Flow Proxy.
In such a scenario, you do not need to go through the proxy. The
go-demoservice could connect to an external DB by setting the env. variableDBto the IP of the database. As long as the database has an IP that can be accessed, the connection can be direct.If you’d still like to connect through a proxy, I can add the option to specify IP of a destination service (at the moment everything is done through service names and overlay network). In that case, I’d appreciate if you’d open an issue in https://github.com/vfarcic/docker-flow-proxy/issues.
Thanks for quick replay and clearing that out for me 🙂 !
Since proxy is not necessary I will not ask for an extra feature of the proxy, thanks.
I am trying to use docker swarm connecting to remote Jenkins (non-docker based)
I could get the slave nodes created with the help of docker swarm service.
But the mount path isn’t getting set in an expected manner.
When I check the newly created slave configuration in the remote Jenkins instance, there is no workspace path being allotted.
Can you please explain what should be source and target for –mount syntax here?
–mount “type=bind,source=/var/run/docker.sock,target=/var/run/docker.sock” \
–mount “type=bind,source=/tmp/,target=/tmp/”
By default, Jenkins agents will use
/workspacedir so you might want to put that as your mount (instead/tmp).tmpshould work as well if you change the workspace dir.No matter which directory you choose, you must make sure that it is available on all the nodes.
Hi Victor,
Is it possible to bypass internal swarm’s load balancing and use haproxy directly for this purpose?
That is possible if you can ensure that HAProxy configuration has IPs of each replica of the service. You’d need a process that would monitor Swarm events and whenever a replica is added or removed, update HAProxy config.
Pingback: Best way to run two docker compose apps behind nginx on one host machine? - QuestionFocus
Hi Viktor,
First of all thanks for the product docker flow proxy. I have used it for my cluster that runs nearly 70 services, more to migrate. However, I am now stuck at a point where I might need your help/suggestion. Till now all the services that I have created/migrated uses HTTP only, so far all good. I have few web app services more to migrate which handles SSL themselves so I’d not need SSL termination at HAProxy instead I’d like HAProxy to do an SSL pass through. I am using all the default values that are mentioned here(https://github.com/vfarcic/docker-flow-proxy/blob/master/Dockerfile)
Here’s how my config for 443 on mode tcp looks like, however it doesnt work and throws a 408 timeout accessing.
frontend tcpFE_443
bind *:443
mode tcp
option tcplog
log global
acl domain_testweb443_2 hdr(host) -i testweb.example.com
use_backend testweb-be443_2 if domain_testweb443_2
backend testweb-be443_2
mode tcp
log global
server testweb testweb:443
Thanks,
Shebin
On the first look, I think that config should work. Can you please post the whole DFP config? Also, I’d suggest you open an issue in https://github.com/vfarcic/docker-flow-proxy/issues. That will allow us easier tracking and discussion.
Thank you Viktor. I have opened an issue for the same with the required details, #423